Basic data flow
Here we describe the basic stages that acquired frames go through, what they do, and how they can be controlled.
Overview
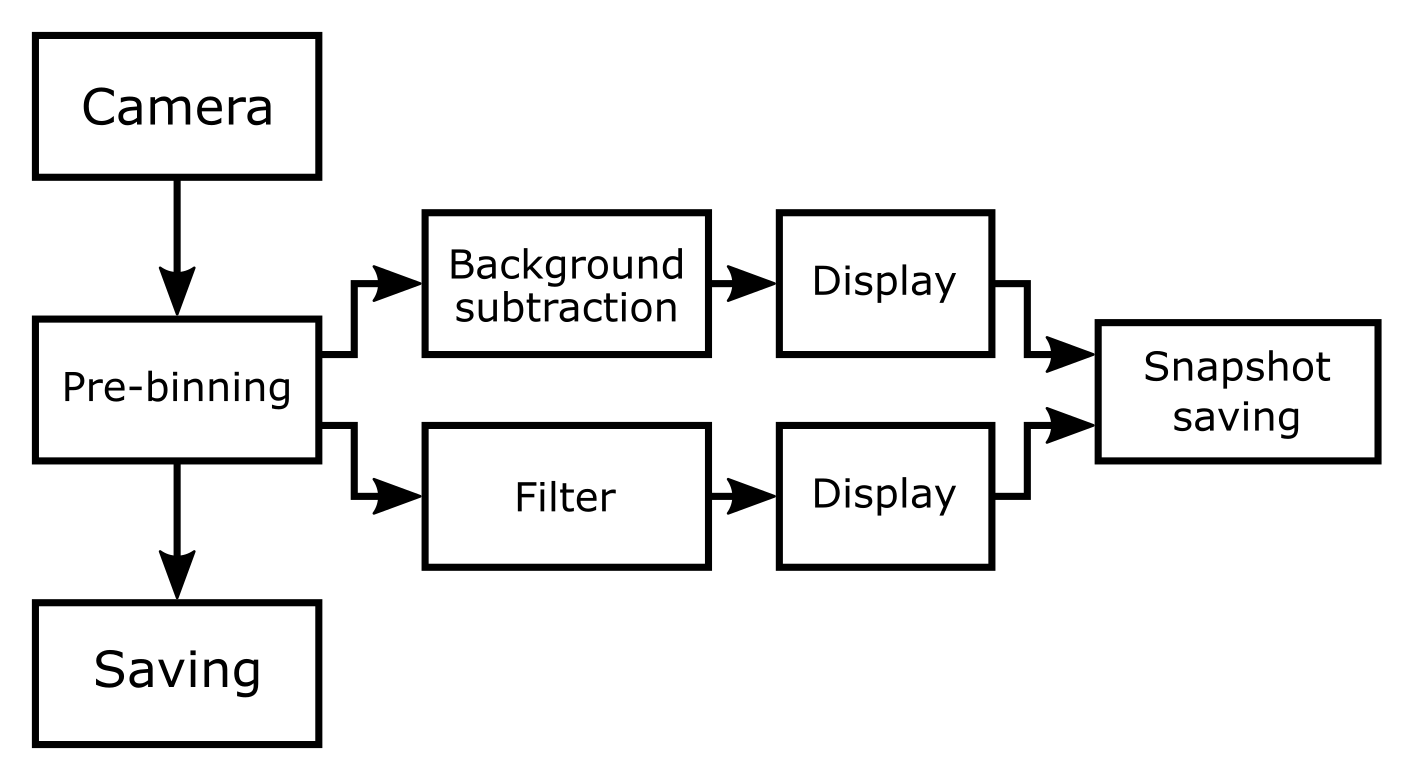
After camera acquisition, the frames undergo several processing stages:
First, the raw camera frames go through the optional pre-binning step, where they are binned spatially and temporally. This step is mostly intended to reduce the load on the further processing or streaming stages which saves processing time and storage space.
After that, the frames are sent directly for saving. All other on-line processing steps (background subtraction, filters, frames slowdown, etc.) only affect the displayed images and snapshot saving, but not the standard data saving.
At the same time, the pre-binned frames are sent to processing stages. One possibility is the built-in background subtraction. The other is custom filters, e.g., Fourier filtering or running average. These are then displayed in corresponding image tabs.
Finally, these displayed images can be saved directly using the snapshot saving. Unlike the standard saving, it saves the processed images exactly like they are displayed, but only one image per file.
These stages above are described in more details below.
Camera
Generally, cameras continuously generate frames at a constant rate as long as the acquisition is running. In addition to the frames themselves, there is an option (enabled i the Advanced tab of the camera settings) to query additional frame info such as shape, index, time stamp (both low-resolution based on PC time and, for some cameras, high-resolution camera-baseed one), etc. Additional details about camera functions such as frame buffer, ROI, or external triggering are available in pylablib documentation.
Pre-binning
This is the first stage after camera acquisition, where the generated frame stream is reduced by binning it. The binning is either temporal, i.e., combining several frames into a single frame, or spatial, combining several pixels in to a single pixel. The available binning modes are skipping (only take the first frame or pixel), summing, taking mean, min, or max.
Pre-binning is generally designed to reduce load on the further processing stages and to shrink the resulting file size. Spatial pre-binning can also partially substitute for camera binning: the effect is mostly the same, although built-in binning typically yields higher signal-to-noise ratio. Temporal sum or mean binning can somewhat increase the camera dynamic range because, unlike increasing exposure, it can avoid saturation.
Note that sum and mean binning can, in principle, result in values not fitting into the standard 16-bit integer used for the frame data, either because of the rounding (for mean) or potential integer overflow (for sum). In this case, there is an option to convert frames to float for further processing and saving. However, this is not always necessary. For example, if the camera has 12-bit pixel depth, you can sum up to a factor of 16 without the fear of overflow, since the maximal image pixel values is 1/16 of the 16-bit integer span.
Saving
Pre-trigger buffer
This is a fairly useful but rarely implemented feature, which essentially allows you to start saving before the saving button was pressed.
The mechanism is similar to the standard operation of any modern digital oscilloscope. The software stores some number n of most recently acquired frames in a buffer, called a pre-trigger buffer. Once the save trigger arrives (e.g., when the Saving button is pressed), the frames from the buffer are stored first, followed by the frames acquired by the camera. This way, the stored data starts n frames before the trigger arrives, which looks as if the saving started in the past.
The amount of the pre-recorded data is controlled by the pre-trigger buffer size n. For example, if the camera is acquiring at the rate 5 kFPS and the pre-trigger buffer size is 10,000 frames, the saved file starts 2 seconds before the trigger.
This feature is very useful when recording rare events. First, it allows recording some amount data before the event is seen clearly, which helps studying how it arises. Second, it means that you do not have to have a fast reaction time and press the button as quickly as possible to avoid lost data.
Naming and file arrangement
Saving can result in one or several data files, depending on the additional settings. By default, the main data file is named exactly like in the specified path, the settings file has suffix _settings, frame info has suffix _frameinfo, and background, correspondingly, _background. Furthermore, if snapshot saving is used, suffix _snapshot is added automatically.
Alternatively, all of the files can be stored in a separate newly created folder with the specified path. In this case, the main data file i s imply named frames, and all auxiliary files lack prefixes.
If the file with the given name already exists and can be overwritten, appended, or the new file will be renamed by adding a number to its name (e.g., frames000.tiff). Appending is generally not recommended, since it is not compatible with all file formats and saving modes, and in any case all auxiliary files such as settings and frame info are completely overwritten.
To avoid name conflicts, it is possible to generate new unique file names based on the specified path and the current date and time. This option allows for easy saving of multiple datasets to unique destinations without changing the destination path. By default, the date and time are added as a suffix, but they can also be added as a suffix or as a new folder, based on the settings file.
File formats
Currently two basic file formats are supported: raw binary and Tiff/BigTiff.
Raw binary is the simplest way to store and load the data. The frames are directly stored as their binary data, without any headers, metadata, etc. This makes it exceptionally easy to load in code, as long as the data shape (frames dimensions and number) and format (number of bytes per pixel, byte order, etc.) are known. For example, in Python one can simply use numpy.fromfile method. On the other hand, it means that the shape and format should be specified elsewhere, so the datafile alone might not be enough to define the content. Note that the settings file (whose usage is highly recommended) describes all the necessary information under save/frame/dtype and save/frame/shape keys.
Tiff and BigTiff formats are more flexible: they store all of the necessary metadata, allow for frames of different shapes to be stored in the same file, and are widely supported. On the other hand, it is a bit slower to write, and require additional libraries to read in code.
Note
Tiff has a limitation of 2 Gb per single file. If file exceeds this size, the saving is interrupted, and the data might be potentially corrupted (either Tiff file by itself will not load, or the frame indices stored in the settings and frame info files will be out-of-sync with the frames). To avoid that, you can either use BigTiff, which does not have this restriction, or file splitting, as described in the saving interface.
In the end, raw binary is more convenient when the data is processed using custom scripts, while Tiff is easier to handle for external software such as ImageJ.
Saving buffer
Many high-speed cameras can generate data faster than it can be saved (about 60 Mb/s for an HDD and about 500 Mb/s for an SSD). In this case, the acquired but not yet saved data is stored in the intermediate saving buffer. This buffer is being simultaneously both filled from the camera and emptied to the drive, which means that its size is only growing as the difference of the two rates. For example, if the camera generates data at 80 Mb/s and it is saved to the drive at 60 Mb/s, the buffer only grows at 20Mb/s. Similarly, if camera generates data at 40 Mb/s, which is lower than the saving rate, then the buffer stays empty, and the streaming can go indefinitely long.
Note
It is important to keep in mind, that the saving is marked as done when all the necessary frames have been placed into the saving buffer, but not necessarily saved. If the frames buffer has some data in it at that point, it will take additional time to save it all to the drive. If another saving is started in the meantime, those unsaved frames will be lost. The filling of the saving buffer can be seen in the saving status.
Snapshot saving
In addition to streaming complete data, there is an option to save the data which is currently displayed. This is done through a separate path, which is independent from the main saving routine; hence, it can be done during ongoing data streaming. Note that, like the standard save, the snapshot also stores all of the additional settings data, but not the frame info or the background.
Background subtraction
Background subtraction can be done in two different flavors. In the “snapshot” subtraction a fixed background frame is acquired and calculated once. In the “running” subtraction a set of n immediately preceding frames is used to generate the background, so it is different for different frames. In either case, the background is usually generated by acquiring n consecutive frames and calculating their mean, median, or (per-pixel) minimal value. Combining several frames usually leads to smoother and more representative background, thus improving the quality, but taking more resources to compute.
The running background subtraction can usually be fairly well reproduced from the saved data, as long as its length is much longer than the background window. However, the same can not be said about the snapshot background, which could have been acquired under different conditions. To account for that, there is also an option to store the snapshot background when saving the data. This saving can be done in two ways: either only the final background frame, or the complete set of n frames which went into its calculation.
Filters
Filters are pieces of Python code, which process the acquired frames and output new images. There are some built-in filters, but they can also be written by a user.